Taking the Next Step
In a Nutshell
We worked on a large scale project for a water and wastewater operator with 7 treatment plants and 139 pumping, monitoring or storage sites. When we entered the project, the infrastructure was automated but compartmentalised. As a result, it was impossible to get a consolidated view of the state of the infrastructure. In the past, several failures had gone undetected as alarming was confined to a specific site. Obviously, this was not an acceptable operational situation. This setup has meant they were not able to respond adequately to critical situations.
That is where our Controlweb came in to implement an efficient centralised system. Wonderware ArchestrA was selected as the SCADA solution, offering centralisation, native redundancy and effective standardisation of the system. The first challenge was to implement a full and standardised SCADA layer over an existing and organically developed control infrastructure. A further challenge was the reliability of communications. The system’s architecture needed to deliver resilience in an environment where communications were expected to drop out.
Some Details
This project was not without its challenges. Each of the sites involved ranged in size, function and IO tag counts They varied from around 20 on the smallest sites to over 1000 on the larger sites. There were also a variety of different hardwares performing the control functions, including Remote Terminal Units and Programmable Logic Controllers.
It meant that we had to present each of the individual components to the system in a consistent fashion, despite their differences. This added an extra layer of complexity as most projects would have consistency built all the way through the control architecture. That was a luxury we just did not have. A simplified view of the ultimate architecture is shown in diagram below.
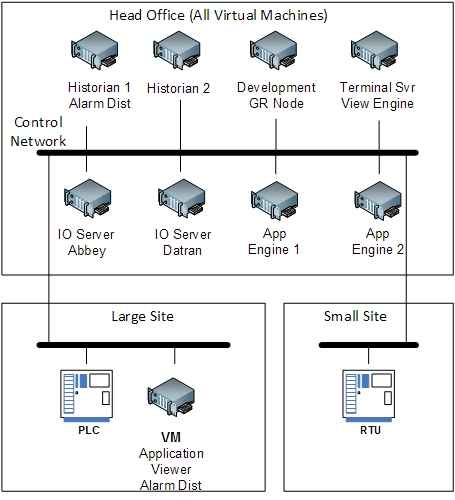
Two important features of the architecture are:
- A control network separated from the corporate network but managed by the IT department, not the controls team. This introduces interesting collaboration challenges.
- All servers deployed as virtual machines. This allows for a further level of resilience inherent with a virtual machine infrastructure.
We focused on 3 key aspects of functionality:
- Alarms – ensuring consistency of alarms and alarm message.
- Communication – early identification of communication problems and an architecture that could deal with this.
- Alarm distribution – with the remote and unmanned nature of the sites, effective distribution of alarm messages to the first response teams was critical. Alarm distribution is separate from and parallel to the alarming received at any operator terminal. A centralised alarm server, historian and development environment were introduced. Primary distribution is handled centrally with local distribution enabled only when there is a communication failure. We made extensive use of virtual machines to run the necessary components. Remote connectivity behind secured network infrastructure also meant that it was no longer necessary to drive to a particular site to make configuration changes. These could be made centrally and deployed to the remote sites as required.
Resilience features included:
- Isolated control network providing improved security with remote connectivity.
- Virtual machine architecture providing hardware resilience.
- Redundant central application engines providing application resilience.
- Redundant historians providing application resilience.
- Local application engines providing communications resilience.
- Local alarm distribution providing communications resilience.
Despite the challenges on this project, we were able to implement an efficient and resilient standardised system across all 139 sites. There is now no chance that faults will go undetected and issues can be corrected from a centralised location. Failure in communication is no longer expected! Our clients were more than impressed with the end result.